What Are AI Candidate Insights and Why Recruiters Can't Ignore Them in 2026
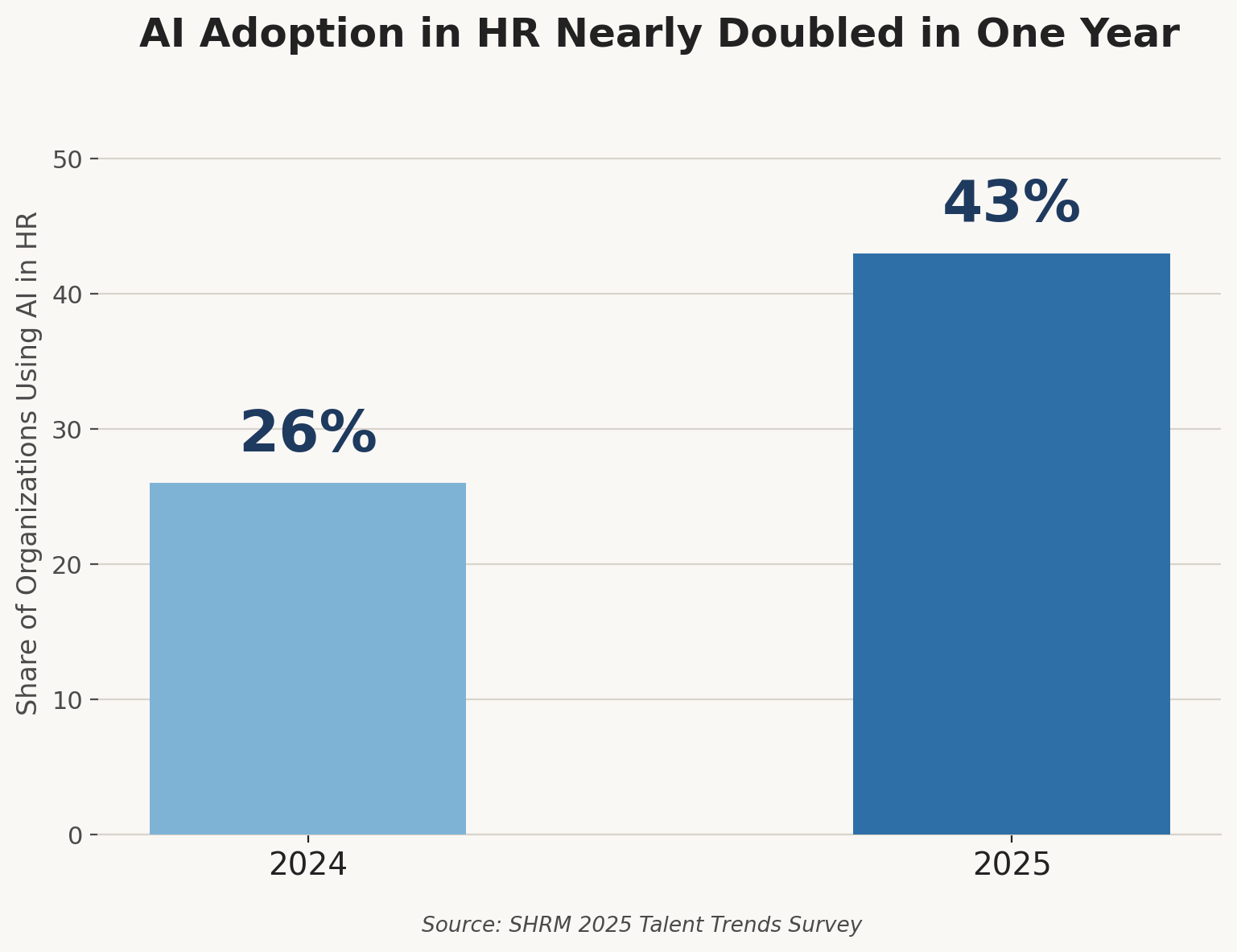
AI adoption inside HR functions nearly doubled in twelve months, climbing from 26% to 43% of organizations, according to SHRM’s 2025 Talent Trends survey. That is not gradual uptake that is a structural shift in how hiring decisions get made.
Most recruiting teams already know how to automate resume screening. Far fewer know how to interpret what the automation is actually telling them. A resume can clear every keyword filter and still belong to a candidate who leaves within four months, or gets rejected by a hiring manager for reasons the filter never captured. That gap between passing a filter and understanding a person is exactly what AI Candidate Insights are built to close.
That gap has widened for a reason most hiring teams haven’t fully priced in yet: the resumes themselves have changed. A growing share of applications are now drafted or heavily polished with AI writing tools, which means resumes increasingly converge on the same phrasing and keyword density regardless of how well a candidate actually fits the role. A filter built to reward keyword match is, in effect, being gamed by the exact tools candidates now use by default which makes the case for insight-based scoring stronger with every hiring cycle, not weaker.
AI is completely transforming talent acquisition. Over 70% of hiring professionals report using generative AI, moving recruitment from degree-based and intuition-heavy processes to skills-first, data-driven decisions
This shift matters because volume alone has stopped being the constraint. Recruiters at startups and SMBs already screen hundreds of applicants per open role using basic automation. The real bottleneck now is judgment at scale knowing which of those pre-screened candidates are actually worth an interview slot, and why.
This blog breaks down what AI Candidate Insights actually are, how they differ from the pass/fail filters most teams already use, where they’ve changed real hiring outcomes, and where their limitations start. If you’re building or buying recruitment technology in 2026, this is the layer that separates a resume database from a decision-support system.
What Are AI Candidate Insights?
AI Candidate Insights are data-driven signals including skill-fit scores, flight-risk indicators, and engagement patterns generated by analyzing a candidate’s resume, application behavior, and interaction history. Unlike a basic filter, insights don’t just include or exclude a candidate; they explain the why behind a ranking, giving recruiters context for faster, more informed decisions.
The distinction matters for anyone comparing tools. A filter answers one question: does this resume meet the minimum bar? An insight answers a harder one: given everything we know about this candidate, how likely are they to succeed and stay?
Insights vs. Filters: The Core Difference
A basic keyword filter checks a resume against a job description and returns a binary result. It cannot tell a recruiter whether a candidate who matches 8 of 10 required skills is a stronger bet than one who matches all 10 but has changed jobs four times in three years.
An insight layer combines multiple weighted signals skills, tenure patterns, response times, assessment performance into a single interpretable score. That score comes with reasoning attached, not just a rank number.
The Core Problem: Screening Volume Without Screening Judgment
Startups and SMBs hiring at scale face a specific version of this problem. A single mid-level opening at a 50-person company can pull 300–500 applications within the first ten days of posting. AI Resume Screening tools solve the intake problem they parse and rank those applications in minutes instead of the 20–30 hours a recruiter would otherwise spend on manual review.
But screening volume down to a shortlist of 15–20 candidates doesn’t solve the harder problem: distinguishing a genuinely strong hire from a resume that is simply optimized for the algorithm. Most teams underestimate this gap by 3–4x. They assume that once a shortlist is generated, the hard part is done. In practice, the shortlist stage is where bad hires most often get missed.
Two forces are compounding this. First, resume quality signals are degrading an estimated 55%+ of job seekers now use AI tools to draft or polish applications, according to multiple 2025 ResumeBuilder surveys, which means resumes increasingly converge on the same keywords and phrasing regardless of actual fit. Second, average time-to-fill in the U.S. still sits near 44 days per SHRM benchmark data, with technical roles frequently exceeding 60 days pressure that pushes recruiters to make faster calls with less information per candidate.
The result is a paradox: recruiters have more applicant data than ever, but less confidence that the data reflects real differences between candidates. That’s the exact gap AI Candidate Insights are designed to close not by adding more filters, but by adding interpretive layers on top of the data already being collected.
There’s also a hidden cost teams rarely put a number on: recruiter attention itself. A talent acquisition lead managing 8–10 open requisitions at once has a finite amount of time to spend per candidate. Industry data puts average initial resume review at roughly 11 seconds per screen, with full evaluation time reaching closer to 90 seconds once a candidate clears the first pass. Spread across 300 applicants, that’s still 7–8 hours of raw review time per requisition time most SMB recruiting teams simply don’t have when they’re also running interviews, coordinating hiring managers, and managing offer negotiations in parallel.
This is precisely why insight scoring, done correctly, isn’t a “nice to have” layered on top of an existing ATS. It’s the difference between a recruiter spending those 7–8 hours reviewing candidates in the order they applied versus reviewing them in the order they’re actually likely to succeed.
How AI Candidate Insights Actually Work
Building a usable insight layer requires more than running a resume through a parser and spitting out a percentage match. It requires combining several distinct signal types, each solving a different piece of the “who should we talk to” question.
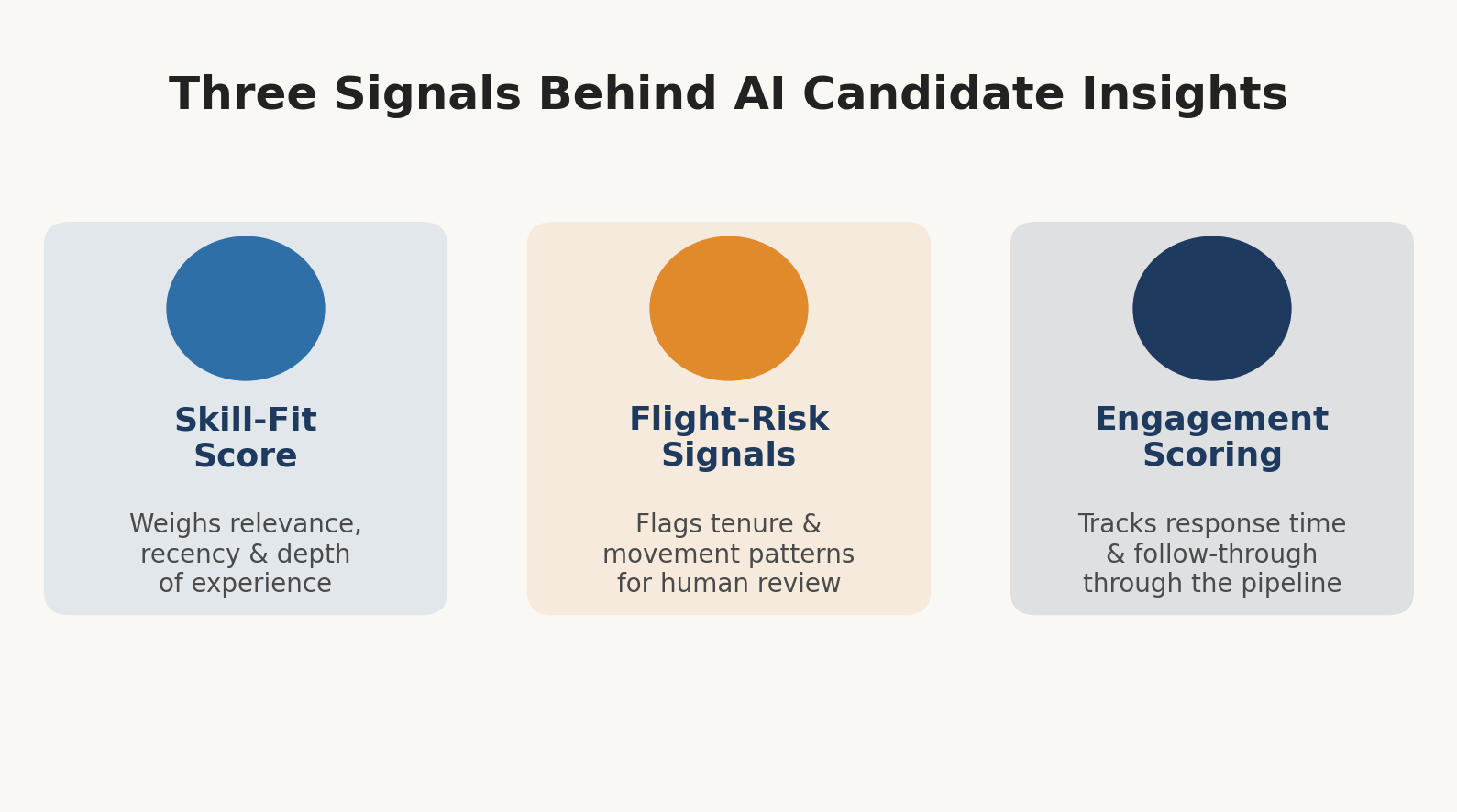
Skill-Fit Scoring
A skill-fit score measures how closely a candidate’s demonstrated experience, not just listed keywords, aligns with the actual requirements of a role. Strong implementations weight recency of experience, depth (years actually spent, not just mentioned), and context (a skill used in a similar company size or industry scores differently than one used in an unrelated setting).
This is where an AI Resume Parser earns its value. Parsing accuracy directly determines insight quality: a parser that misreads job titles, misses employment gaps, or fails to normalize skill synonyms (e.g., “GCP” vs. “Google Cloud Platform”) will produce a skill-fit score built on bad inputs. Parsing accuracy benchmarks across major platforms currently sit in the 89–94% range for structured resumes, dropping meaningfully for non-standard formats like design portfolios or academic CVs.
Weighting decisions matter as much as the underlying data. A skill-fit model that treats every listed skill as equally important will rank a candidate who lists 15 tangential skills above one who lists 6 directly relevant ones, the opposite of what a hiring manager actually wants. Stronger implementations apply a decay function to skill recency (a skill last used five years ago counts for less than one used in the past twelve months) and a depth multiplier tied to how long a skill was actually applied versus briefly mentioned on a single project.
There’s a compliance dimension here too. Under frameworks like the EU AI Act, which classifies hiring algorithms as high-risk systems, and emerging U.S. state-level rules requiring bias audits on automated employment decision tools, the weighting logic behind a skill-fit score needs to be documented and explainable, not just accurate. A score a recruiter can’t explain to a rejected candidate, or to a regulator, is a liability regardless of how well it performs statistically.
Flight-Risk Signals
Flight-risk signals estimate the likelihood a candidate will leave a role within the first 12–18 months, based on patterns like job tenure history, frequency of lateral moves, gaps between roles, and available engagement behavior during the recruitment process itself (response speed, interview scheduling flexibility, salary negotiation patterns).
This is inherently probabilistic, not deterministic. A candidate with three jobs in four years might be a contractor by design, not a flight risk. Good flight-risk models flag a signal for human review rather than auto-rejecting on tenure pattern alone.
Engagement Scoring
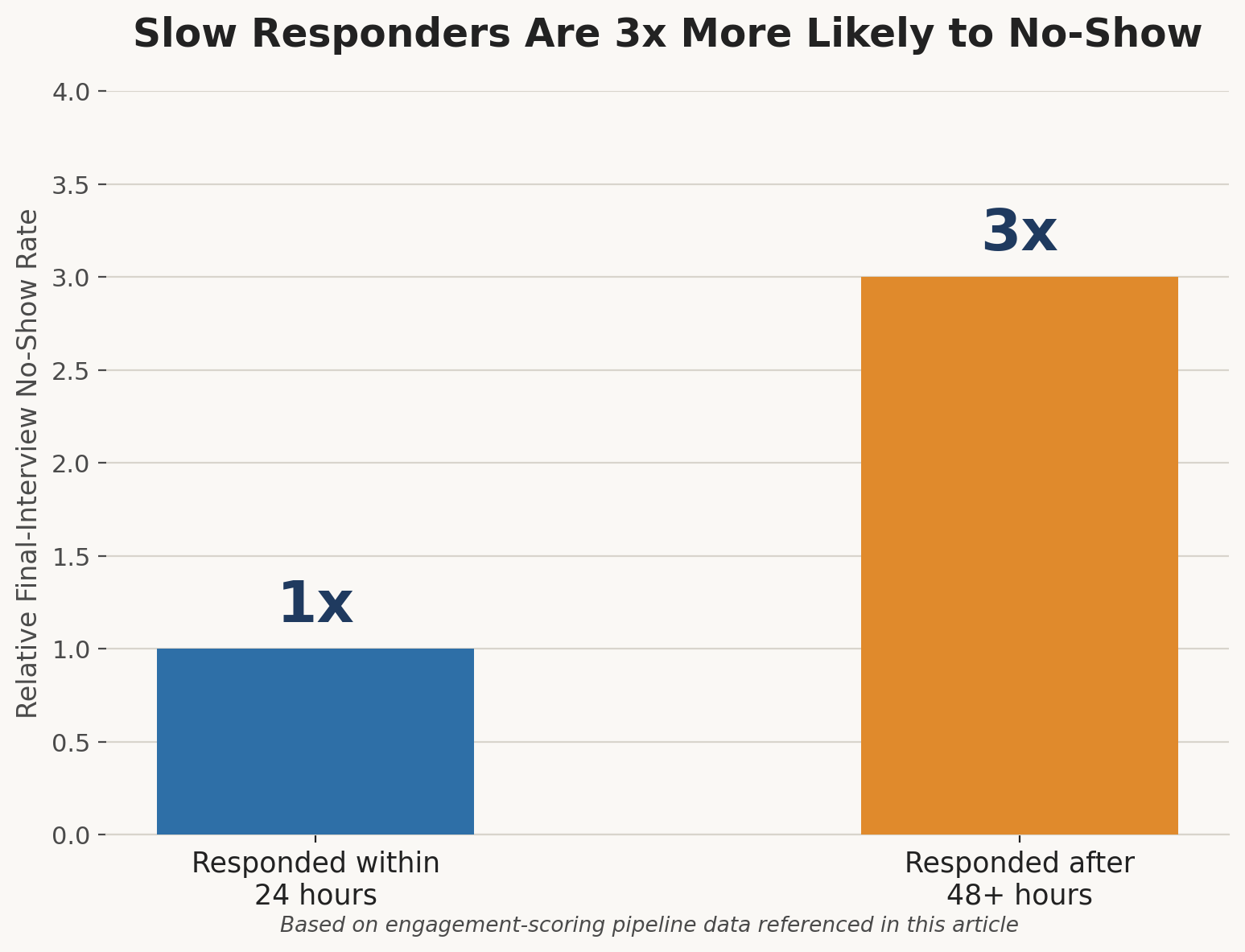
Engagement scoring tracks how a candidate interacts with the hiring process itself, email open rates, response latency, assessment completion time, and interview attendance reliability. Low engagement scores often correlate with higher no-show rates at later interview stages, which matters directly for time-to-hire math: a single last-minute no-show at the final round can add 7–10 days back onto a filled requisition.
Engagement data becomes more useful the earlier it’s captured. A candidate who takes four days to schedule an initial 20-minute screening call is sending a signal distinct from one who books within an hour, even if both candidates score identically on skill-fit. Neither signal alone justifies a decision, but combined with other data points, engagement scoring helps recruiters prioritize outreach toward candidates most likely to follow through to an offer.
Candidate Profile Management as the Foundation
None of these signals are useful in isolation, updated once, and forgotten. Candidate Profile Management is the practice of maintaining a living, centralized record for each applicant’s resume data, interview notes, assessment scores, and status history so that insights stay current as a candidate moves through the pipeline rather than reflecting a stale snapshot from application day.
Without centralized profile management, insight scores decay fast. A candidate who scored well on initial skill-fit but failed a technical assessment two weeks later still shows up as “high fit” in a system that isn’t updating the profile in real time. This becomes a bigger problem the longer a pipeline runs a 45-day hiring cycle means an initial skill-fit score is, by the final decision point, over six weeks stale unless the profile has been actively updated with each new interaction.
Centralized profiles also solve a secondary problem specific to growing teams: institutional memory. When a recruiter leaves or a role gets reassigned mid-search, a well-maintained candidate profile lets a new team member pick up exactly where the previous one left off, without re-reading a scattered email thread or re-running an assessment that’s already been completed.
The Practical Build Process
Teams evaluating or building an insight layer typically move through the same sequence:
- Standardize intake data ensure resumes, applications, and assessment results feed into one structured schema rather than scattered spreadsheets or email threads.
- Deploy accurate parsing validate resume parser accuracy against a sample of 50–100 known-good resumes before trusting output at scale.
- Define scoring weights per role skill-fit weighting for an engineering role should differ from a sales role; generic scoring models underperform role-specific ones by a wide margin.
- Layers in behavioral signals add flight-risk and engagement data only after skill-fit scoring is validated, since behavioral signals are noisier and easier to misread in isolation.
- Keep a human decision gate insights should inform shortlist ranking, not auto-reject candidates without recruiter review, both for accuracy and for compliance reasons covered later in this piece.
- Audit for drift quarterly scoring models trained on historical hiring data can quietly encode past bias; recheck outcomes against actual performance data every 90 days.
Cost implications scale with sophistication. A lightweight AI Resume Screening layer for a 20-person hiring team typically runs on a flat-rate ATS subscription with screening built in, while custom-built scoring models with proprietary weighting can run into five- and six-figure annual licensing for enterprise-scale deployments.
Case Study: Where Insights Changed a Real Hiring Decision
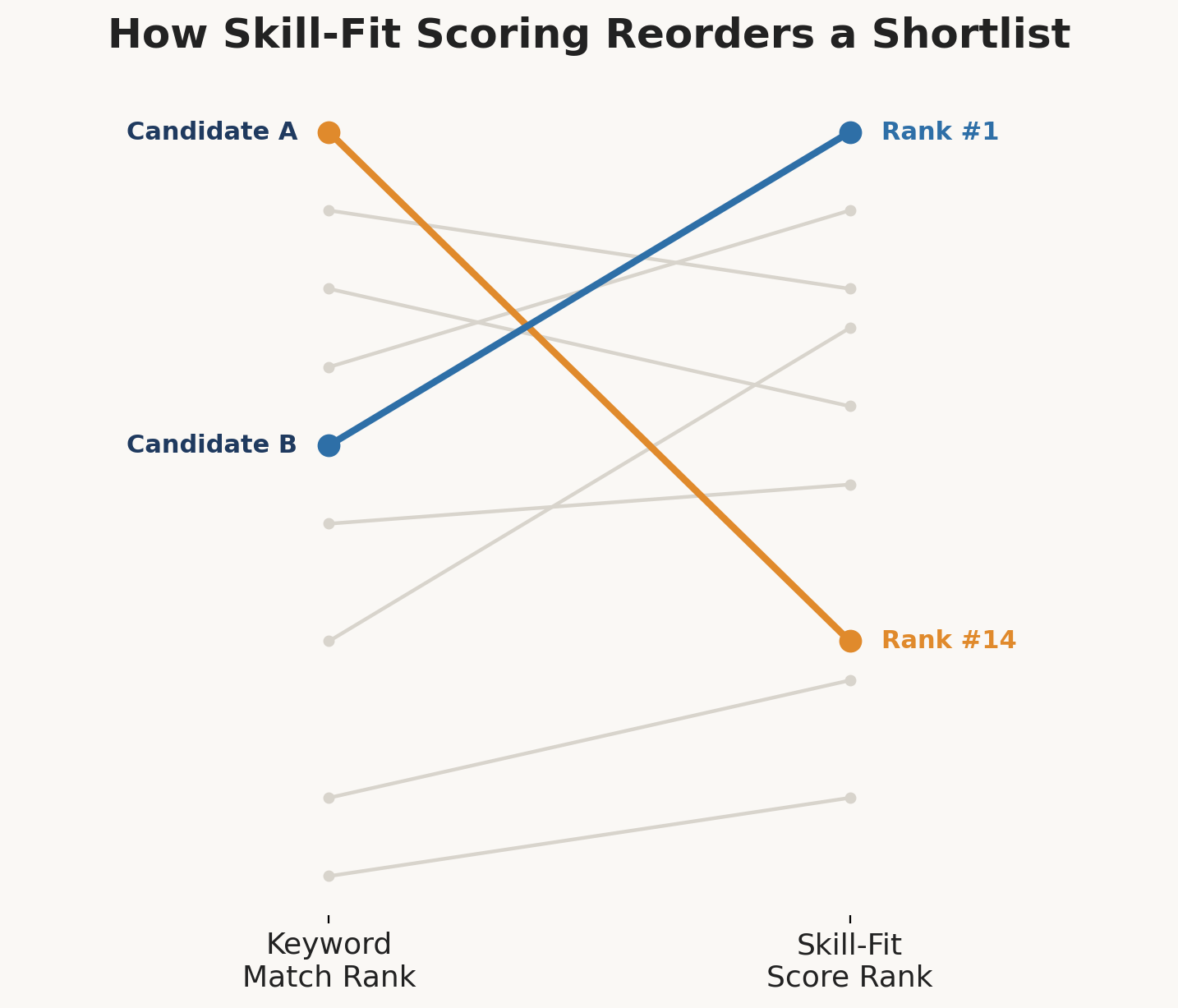
A 60-person SaaS startup hiring for a senior backend role received 340 applications in nine days. Basic keyword filtering shortlisted 22 candidates, all showing 90%+ keyword match against the job description. Skill-fit scoring, applied on top of that shortlist, reordered the ranking substantially the candidate ranked #1 on keyword match dropped to #14 once recency and depth of relevant framework experience were weighted, while a candidate ranked #9 on keywords moved to #1. That candidate was hired and remained in the role past the 18-month mark, a retention outcome the hiring manager credited directly to the reweighted shortlist rather than the original resume ranking.
A second scenario: a 15-person recruiting team at a fintech SMB used flight-risk signals to flag a candidate with strong technical scores but a pattern of four job changes in three years, each lasting under 10 months. Rather than auto-rejecting, the recruiter used the flag to ask targeted interview questions about the pattern. The candidate explained a legitimate reason tied to two rounds of company layoffs, not performance. The hire was made, and the flight-risk flag became a documented example the team now uses to train new recruiters on reading signals as prompts, not verdicts.
A third pattern shows up repeatedly in high-volume hiring: engagement scoring catching candidates likely to ghost the process. One recruitment team tracking response-time data found that candidates taking longer than 48 hours to respond to an initial screening request had a no-show rate at final interviews roughly three times higher than candidates responding within 24 hours data that now shapes how far in advance they schedule final-round interviews, and which candidates get a confirmation call the day before.
A fourth, smaller-scale example illustrates the limitation as much as the benefit. A retail-tech startup relied heavily on skill-fit scoring alone for a customer support hiring push and, three months in, noticed retention among AI-recommended hires was no better than the team’s previous manual process. The root cause traced back to a scoring model that weighted technical tool familiarity heavily but had no signal for communication style, a variable that mattered more for the role than any resume-visible skill. The team’s fix was straightforward: they added a short structured assessment focused on communication scenarios and fed those results back into the candidate profile, which corrected the gap within the next two hiring cycles.
Comparison Framework: Filters vs. Insights vs. Manual Review
Choosing between approaches depends on hiring volume, role complexity, and how much recruiter time is available per requisition.
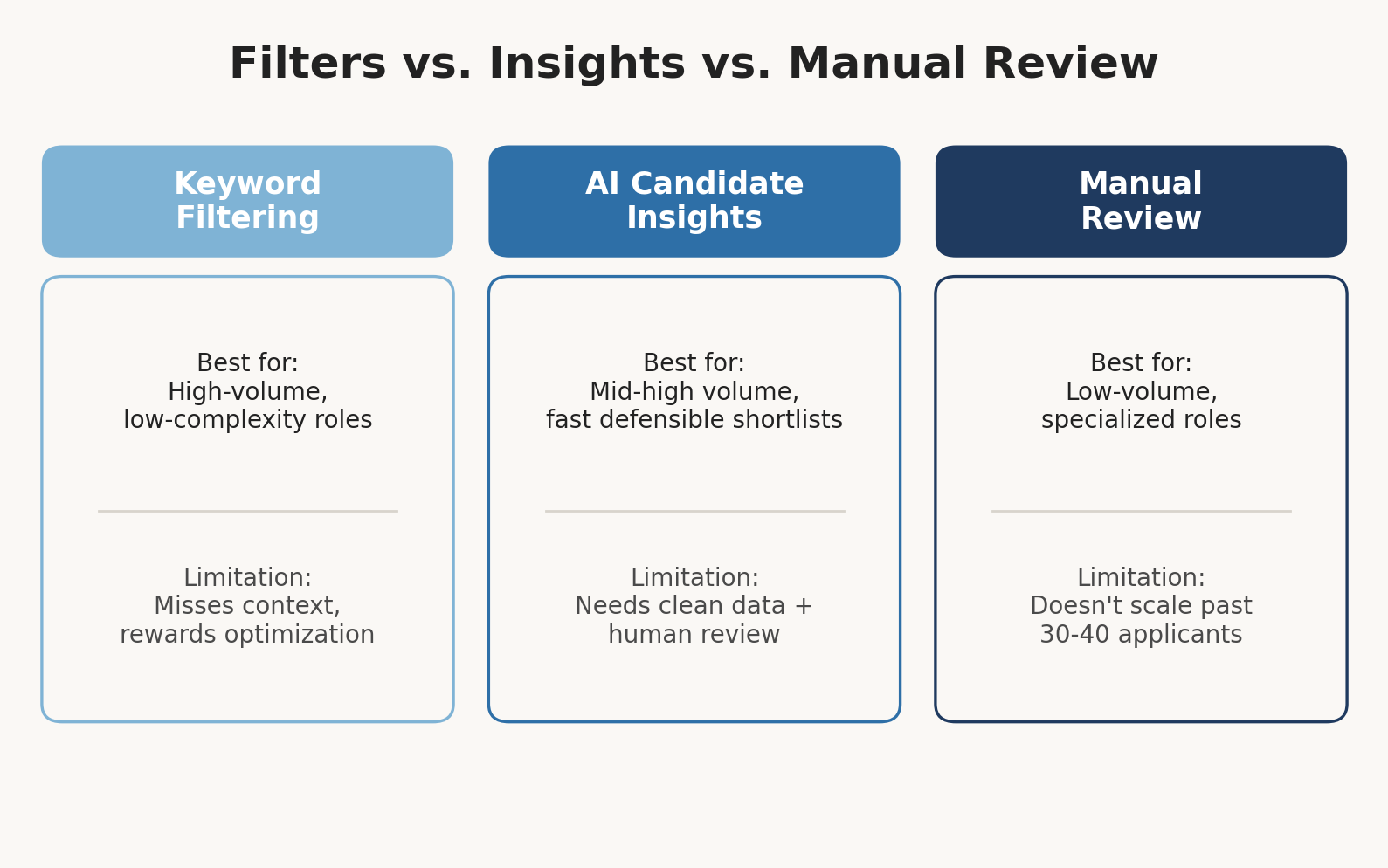
| Approach | Best For | Key Limitation |
| Keyword/Boolean filtering | Very high-volume, low-complexity roles | Misses context; rewards resume-optimization over fit |
| AI Candidate Insights | Mid-to-high volume roles needing fast, defensible shortlists | Requires clean input data and human review to avoid bias drift |
| Manual resume review | Low-volume, highly specialized, or executive roles | Doesn’t scale past 30–40 applications per opening without added headcount |
Most SMB teams land on a hybrid: automated parsing and insight scoring for the first pass, manual review for the final shortlist. This split matters because it protects against the two failure modes on either extreme pure automation that can silently entrench bias, and pure manual review that simply can’t keep pace with 300+ applications per role without recruiters burning out or delaying every other requisition on their plate.
The decision point most teams miss is where to draw the line between automated and manual stages. Setting the automated cutoff too aggressively (for example, auto-rejecting anyone below a fixed skill-fit threshold) risks screening out strong candidates whose resumes simply don’t parse cleanly career changers, non-traditional backgrounds, or candidates from industries with different terminology conventions. A safer default is using insight scores to rank the full applicant pool rather than to eliminate anyone outright, leaving the final cut to a recruiter reviewing the bottom of the shortlist alongside the top.
This is also where Recruitment Status Update Software earns its place once a shortlist is set, automated status updates, interview reminders, and rejection notices keep candidates informed without adding manual follow-up work, which directly affects offer-acceptance rates and employer brand. Candidates who receive timely, personalized status updates are measurably less likely to drop out of a process mid-pipeline, and automated reminders reduce the scheduling back-and-forth that otherwise eats into recruiter time saved by insight scoring in the first place.
What Most Teams Get Wrong
The most common mistake isn’t over-trusting AI scoring, it’s treating insight scores as static. A skill-fit score generated at application time is a snapshot, not a verdict. Teams that re-run scoring after an interview or assessment consistently catch mismatches that the initial pass missed.
The second mistake is deploying a single scoring model across every role type. A model tuned on data from sales hires will misjudge engineering candidates and vice versa tenure patterns, skill depth signals, and even engagement benchmarks vary meaningfully by function. Teams that see the strongest results build or select tools that allow per-role weighting rather than a one-size-fits-all score.
The third, and most consequential, mistake is removing the human decision gate entirely. Only 26% of job applicants say they trust AI to evaluate them fairly, according to Gartner survey data cited across multiple 2025–2026 HR research reports. Auto-rejecting candidates based solely on an algorithmic score without a recruiter reviewing edge cases creates both a fairness problem and, increasingly, a compliance exposure as jurisdictions from the EU to New York City introduce bias-audit requirements for hiring algorithms.
Limitations and ethics deserve direct treatment here. AI scoring models are trained on historical hiring data, which means they can replicate past patterns of bias if left unchecked, a documented risk in several public cases where automated screening tools downgraded candidates based on proxies correlated with gender or employment gaps. Insight scores should function as a starting point for recruiter judgment, not a replacement for it, and any scoring model in production should be audited against actual post-hire performance data on a recurring basis.
A fourth, subtler mistake is treating insight scores as more precise than they actually are. A skill-fit score of 82 versus 79 is rarely a meaningful difference, both fall within the model’s margin of error, and treating a three-point gap as decisive is a common way small biases in the underlying data get amplified into hiring outcomes. Teams that get the most value from insight scoring use score bands (strong fit, moderate fit, needs review) rather than treating exact numbers as rankable to the decimal point.
Where This Leaves Recruiting Teams in 2026
Screening automation solved the volume problem years ago. The teams pulling ahead now are the ones using insight layers to make the shortlist stage itself smarter, turning a pile of “qualified” resumes into a ranked, reasoned list a recruiter can act on in minutes rather than hours.
If you’re evaluating whether your current ATS gives you insights or just filters, the fastest test is this: ask why a candidate ranked where they did. If the answer is a percentage with no reasoning attached, you’re still working with a filter. Hirium’s AI-powered screening and shortlisting layer is built specifically to answer that “why,” with a forever-free plan for teams that want to test it against their current process before switching anything over.
FAQ
What are AI candidate insights?
AI Candidate Insights are derived signals such as skill-fit scores, flight-risk indicators, and engagement scores generated by analyzing resume data and candidate behavior throughout the hiring process. They give recruiters context and reasoning behind a ranking, rather than a simple pass/fail result.
How is this different from basic resume filtering?
Basic filtering checks whether a resume contains required keywords and returns a binary match result. Insights combine multiple weighted signals into an interpretable score with reasoning attached, allowing recruiters to compare candidates who all technically “pass” a filter but differ significantly in actual fit.
Are AI-generated candidate scores accurate?
Accuracy depends heavily on input data quality. Resume parsing accuracy across major platforms typically ranges from 89–94% on structured resumes, but drops for non-standard formats. Scores should be treated as directional signals for recruiter review, not final decisions.
Is it ethical to score candidates with AI?
It can be, provided the model is regularly audited for bias, a human reviews edge cases before rejection, and candidates are given transparency into how they’re being evaluated. Only 26% of applicants currently trust AI to evaluate them fairly, which makes transparency a practical necessity, not just an ethical preference.
What is a skill-fit score?
A skill-fit score measures how closely a candidate’s actual demonstrated experience factoring in recency and depth, not just keyword presence, matches the requirements of a specific role. It differs from keyword matching by weighting context and relevance rather than simple term overlap.
Can AI actually predict flight risk?
It can flag statistical patterns correlated with shorter tenure, such as frequent job changes or specific gap patterns, but these are probabilistic signals, not certainties. Flight-risk flags work best as a prompt for a targeted interview question rather than an automatic disqualifier.
Do small hiring teams need this, or is it only for enterprise recruiting?
Startups and SMBs often need it more acutely than enterprises, since they typically run high applicant volume against small recruiting teams with no dedicated data or people-analytics function. A forever-free ATS with built-in AI screening and insight scoring can close that gap without enterprise-level budget or headcount.
How long does it take to see results after adopting AI candidate insights?
Most teams see a measurable reduction in time spent per shortlist within the first hiring cycle, since insight scoring removes the manual re-reading of resumes that already passed a basic filter. Improvements in actual hire quality and retention take longer to confirm typically one to two full hiring cycles, since retention outcomes only become visible after new hires have been in the role for several months.