How to Clean Up a Messy Candidate Database Without Losing Good Profiles
A recruiting team sitting on 40,000 candidate records can typically produce a qualified shortlist from fewer than 3,000 of them. The other 37,000 are duplicates, dead email addresses, three-year-old job titles, or profiles nobody ever tagged. Database size and database usability are not the same metric, and most hiring teams only discover the gap when a recruiter spends 45 minutes searching for a candidate who was sourced twice under two different email addresses.
Most talent acquisition teams treat this as background noise until it starts costing interviews. A strong candidate applies for a role, gets missed because their older profile was tagged “not a fit” from a 2023 search, and the team re-sources externally for a role that was already sitting in their own pipeline. This is not a sourcing failure. It is a candidate database cleanup failure, and it is far more common and far more fixable than most hiring leaders assume.
That’s where Candidate Database Cleanup becomes essential. Instead of continuously sourcing new candidates, teams can unlock value from their existing database if the data is structured, searchable, and reliable.
The need is growing fast: according to IBM Data Quality Report, poor data quality costs organizations an average of $12.9 million annually, with duplicate and outdated records being a major contributor across enterprise systems.
It is also rarely anyone’s fault in isolation. A database gets messy gradually, one unmerged duplicate and one un-updated status at a time, across dozens of recruiters and hundreds of requisitions over several years. No single hire or process caused it, which is exactly why no single recruiter tends to fix it without a defined project and a defined owner.
This guide walks through the signs that a database needs attention, a five-step cleanup process, the deduplication logic that actually works, a tagging taxonomy you can implement in a week, and the automation layer that prevents the mess from returning. None of it requires ripping out an existing ATS; most of it can be layered onto whatever system a team is already using, provided the system supports structured tagging and rule-based matching.
What Is Candidate Database Cleanup?
Candidate database cleanup is the structured process of auditing, deduplicating, updating, and tagging candidate records inside an applicant tracking system so that every profile is accurate, searchable, and reflects a candidate’s true status. It removes redundant and stale data while preserving legitimate, reusable candidate history. Done correctly, it improves search accuracy without deleting profiles that still hold hiring value.
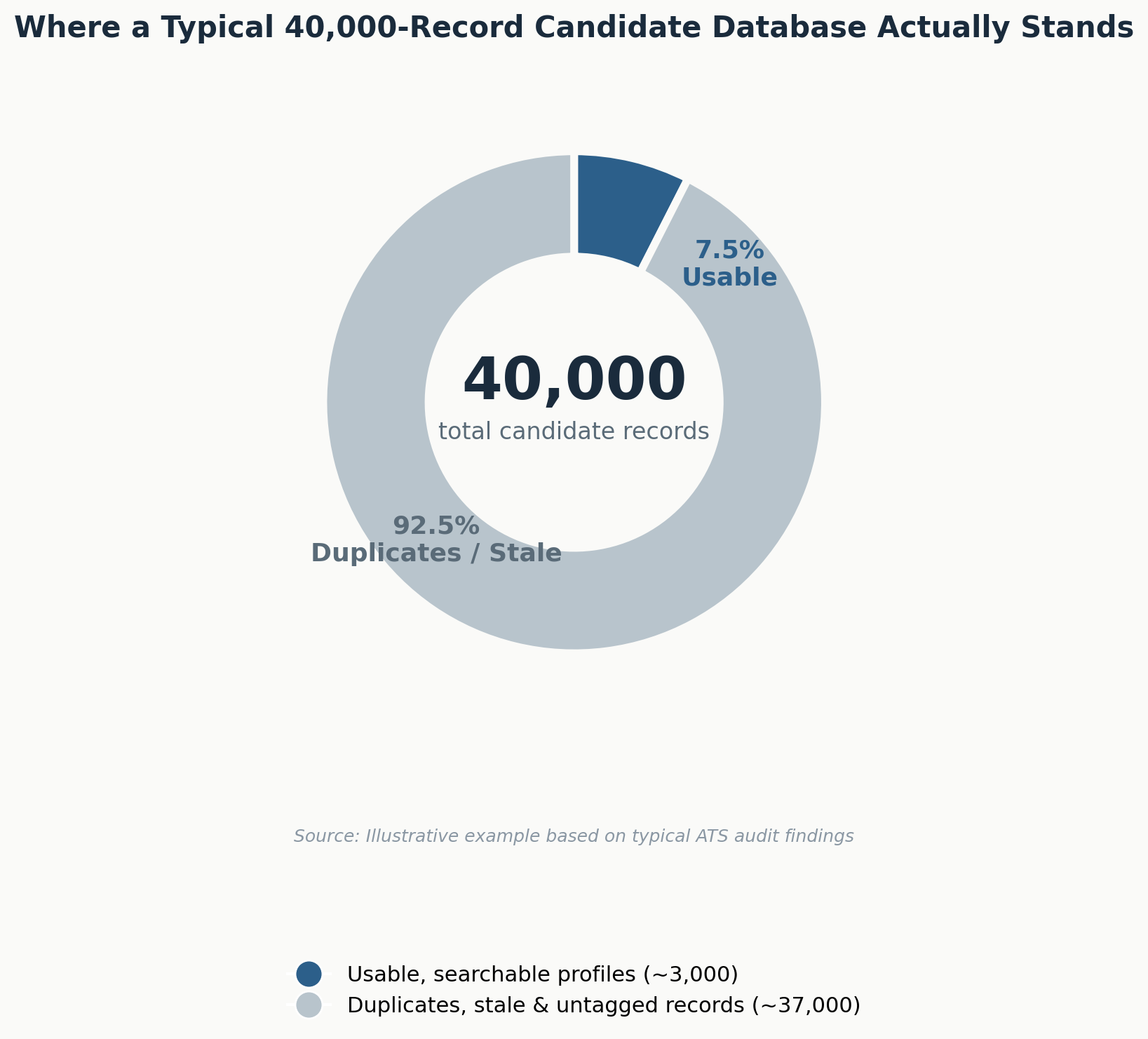
The Real Business Problem Behind a Messy Database
Most teams underestimate the scale of this problem by 3 to 4x. A hiring manager who assumes 5% of records are duplicates is usually looking at 15% to 20% once a proper audit runs, particularly in databases that have absorbed multiple sourcing channels, job boards, referrals, LinkedIn, career pages, and manual recruiter uploads without a shared matching rule.
The operational cost shows up in three places. First, candidate profile management breaks down when recruiters cannot trust that a search actually surfaces every relevant person, so they re-source candidates who are already in the system. Second, screening slows down: a recruiter reviewing 300 to 500 resumes for a single role, a volume consistent with published hiring benchmarks, cannot afford to manually cross-check each one against existing records. Third, compliance risk increases, since outdated contact details and stale consent records make it harder to demonstrate that candidate data is being handled correctly under data protection rules.
There is also a slower, less visible cost: candidate experience. A strong applicant who gets contacted twice by two different recruiters for the same role, or who is told “we have no record of your application” after applying six months earlier, forms an impression of the company before an interview ever happens. For startups and SMBs competing for the same senior hires as larger companies, that first impression carries more weight, not less.
The timeline pressure makes this worse. A team trying to fill a role in 30 to 45 days does not have the bandwidth to manually cross-reference every new applicant against 15,000 existing records, so the database keeps growing messier under exactly the conditions urgency, volume, multiple recruiters working the same requisition that make cleanup least convenient and most necessary. By the time hiring slows down enough for someone to “get to it,” the record count and duplicate rate have both grown, and what would have been a two-day fix becomes a two-week project.
Budget conversations tend to surface the problem too late. A candidate database cleanup initiative rarely gets scheduled proactively; it usually gets triggered by a specific failure, a client complaint about being contacted twice, a compliance audit that flags outdated consent records, or a new head of talent acquisition who inherits a database nobody trusts. Building cleanup into a recurring calendar, rather than waiting for a trigger event, is significantly cheaper in both time and tooling cost than treating it as emergency remediation.
How to Actually Run a Candidate Database Cleanup
This is the section most guides skip past with vague advice like “regularly review your data.” A real cleanup requires a defined sequence, clear deduplication logic, and a tagging system that survives contact with daily recruiting work. Here is the process broken into its component parts.
Signs Your Database Is Messy
Before running a cleanup, confirm the database actually needs one. Four signals reliably indicate a database is overdue:
- Duplicate records at scale. The same candidate exists under two or more profiles because they applied through a career page and were also sourced from LinkedIn, or applied twice with a personal and a work email.
- Stale records with no recent activity. Profiles untouched for 18 months or longer, often for roles the company no longer hires for, with no indication of whether the candidate is still relevant or reachable.
- Missing or inconsistent tags. Some candidates are tagged by skill, others by source, others not at all, making filtered search unreliable and forcing recruiters to read full resumes instead of searching structured fields.
- Status fields that do not reflect reality. Candidates marked “in process” for roles that closed eight months ago, or marked “rejected” from one requisition even though they are a strong match for a currently open one.
If two or more of these show up consistently during a spot-check of 50 to 100 random records, the database needs a structured cleanup, not a quick manual pass.
Compliance and Integration Considerations
A cleanup is also the moment to address data-retention exposure. Many regions require that candidate data not be kept indefinitely without a documented basis, which means an audit should flag records past a defined retention window (commonly 12 to 24 months, depending on jurisdiction and internal policy) for review rather than letting them sit untouched by default. Archiving with a clear retention rule attached solves both the searchability problem and the compliance problem in the same pass.
Integration points matter just as much as the data itself. If candidates flow in from a career page, a job board, a referral form, and a sourcing extension, each of those channels needs to write into the same underlying schema, same field names, same status values, same tag structure or the database will re-fragment within months of being cleaned. Before running a cleanup, it is worth confirming that every intake source maps to one consistent data model rather than assuming the ATS will reconcile the differences automatically.
The 5-Step Cleanup Process
- Audit and baseline the database. Pull a full export or run a database-level report to measure total record count, duplicate rate, percentage of records with no activity in the last 12 months, and percentage of records missing key fields (email, phone, current status, skill tags). This baseline is what proves ROI once the cleanup is complete.
- Run deduplication using layered matching logic. Do not rely on an exact email match alone layer in name plus phone number, and fuzzy name-plus-company matching, to catch duplicates created through alternate email addresses or minor spelling variations.
- Merge, don’t delete, wherever history has value. When two records represent the same person, merge activity history, notes, and resume versions into a single profile rather than deleting the older one outright, the goal is one accurate record per candidate, not fewer records overall.
- Standardize and apply the tagging taxonomy. Every surviving profile should carry a consistent set of tags: skill or role category, source channel, current pipeline status, and last-activity date. Inconsistent tagging is the single biggest driver of database rot after duplication.
- Archive rather than delete stale records. Candidates inactive for 18 to 24 months with no current relevance can be moved to an archived state rather than permanently removed, preserving them for future searches while keeping the active database lean.
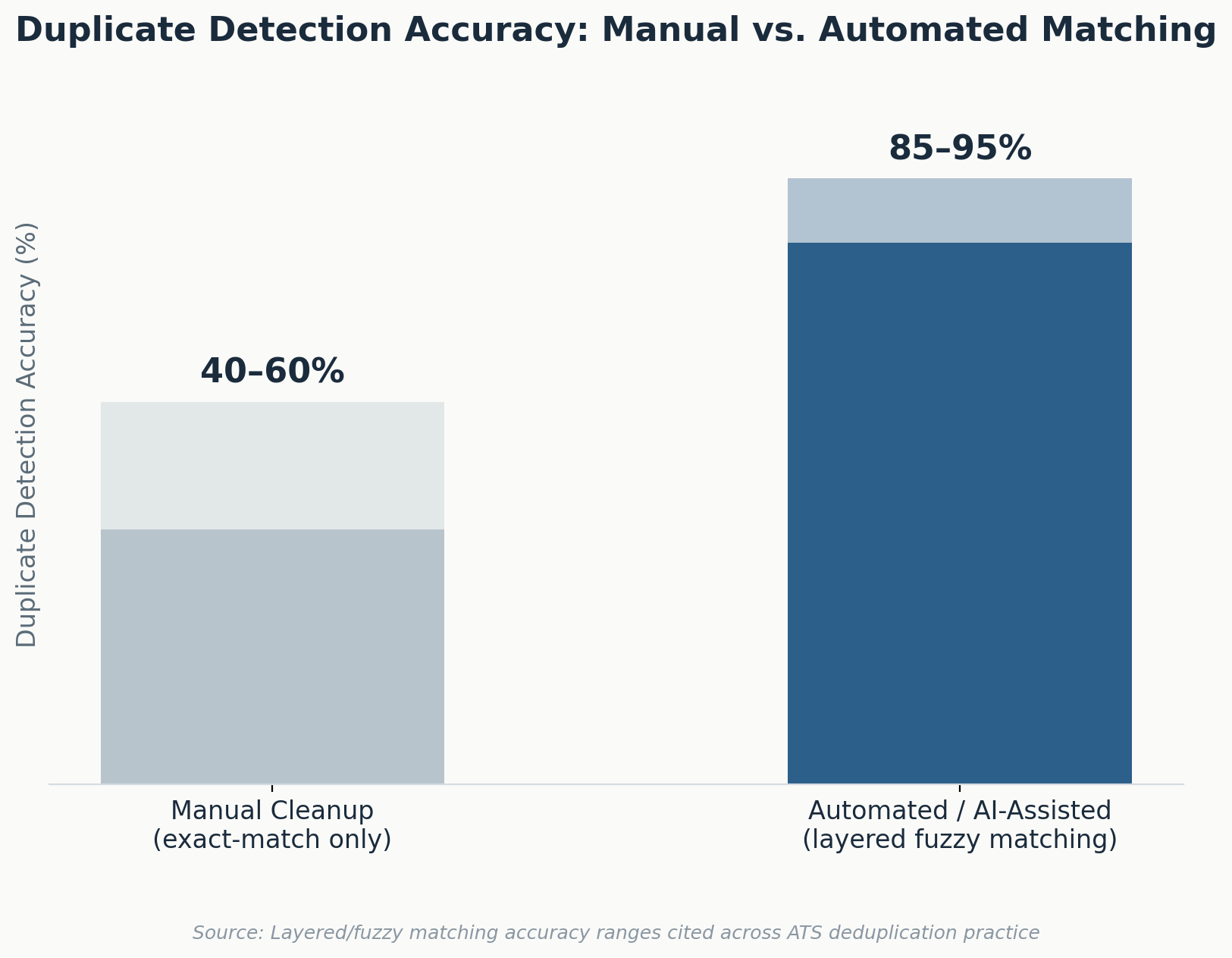
Deduplication Logic Explained
The mechanics of deduplication determine whether a cleanup actually works or just moves the mess around. Exact-match logic checking only for an identical email address typically catches 40% to 60% of true duplicates, because candidates frequently apply with a personal email the first time and a work email the second.
Layered matching logic closes that gap by scoring multiple fields together: name similarity, phone number match, resume content overlap, and employer history. A record scoring above a defined confidence threshold (commonly 85% to 90% similarity across fields) gets flagged for automatic or reviewed merge, while anything below that threshold is queued for manual recruiter confirmation rather than auto-merged, which prevents two genuinely different candidates with similar names from being incorrectly combined.
The cost implications of getting this wrong run in both directions. Setting the confidence threshold too low creates false merges, where two different candidates get combined into one profile and one of them effectively disappears from search. Setting it too high leaves genuine duplicates unmerged, which defeats the purpose of the cleanup. Most recruiting teams find that a two-tier system auto-merge above 90% confidence, human review between 70% and 90%, no action below 70% balances accuracy against recruiter workload without requiring every match to be manually checked.
Building a Candidate Database Tagging Taxonomy
A tagging taxonomy is only useful if it is simple enough that recruiters actually apply it during daily work, not just during a cleanup sprint. A workable structure uses four tag categories:
- Function/skill tag (e.g., “Backend Engineer,” “Growth Marketer”) to support role-based search
- Source tag (e.g., “Referral,” “Career Page,” “LinkedIn Sourced”) to support source-effectiveness reporting
- Pipeline status tag (e.g., “Active,” “On Hold,” “Not a Fit Reusable,” “Not a Fit Do Not Contact”) to prevent good candidates from being buried under a single generic rejection label
- Recency tag or auto-timestamp to flag records that have gone stale and need review
The “Not a Fit Reusable” distinction matters more than most taxonomies account for. A candidate who was strong but lost out to another finalist is fundamentally different from one who was never qualified, yet most databases tag both the same way which is exactly how good profiles get lost during a cleanup.
Keep the taxonomy to a fixed list of allowed values per category rather than free text. Free-text tagging feels flexible at the moment, but it is the reason most databases end up with variations like “Sales,” “sales,” “Sales Rep,” and “AE” all describing the same function, none of which reliably surface together in a filtered search.
How an AI Resume Parser Prevents Future Mess
An AI resume parser addresses the root cause rather than the symptom. Instead of a recruiter manually re-typing a candidate’s name, skills, and work history into the system the exact process that introduces spelling variations and duplicate-triggering inconsistencies the parser extracts structured fields directly from the resume and checks them against existing records before a new profile is created.
This matters most at volume. A team receiving 300+ applications per open role cannot manually screen for duplication at the point of entry; automated parsing does this in the seconds between submission and storage, catching the alternate-email and near-identical-name cases that manual review misses.
Workflow Automation Software for Ongoing Hygiene
A cleanup that is not paired with workflow automation software degrades again within 6 to 9 months, because the manual habits that created the mess in the first place are still in place. Automated workflows close this gap in three specific ways: auto-flagging records with no activity after a defined period, auto-applying status changes when a candidate moves stages (removing the need for manual status updates that often get skipped), and running scheduled deduplication scans rather than relying on someone remembering to do it quarterly.
Paired with recruitment status update software, this also solves the candidate-experience problem directly. When a candidate’s stage changes, an automated status update and notification go out without a recruiter needing to remember, which keeps the same profile current instead of allowing it to silently go stale while the recruiter’s attention moves to the next requisition.
The combined effect of parsing and automated workflows is that a candidate database cleanup stops being a recurring project and becomes a maintained state. Instead of scheduling a cleanup sprint every 12 to 18 months, the system enforces the standards continuously, and the periodic audit becomes a check on the automation rather than a full manual rebuild.
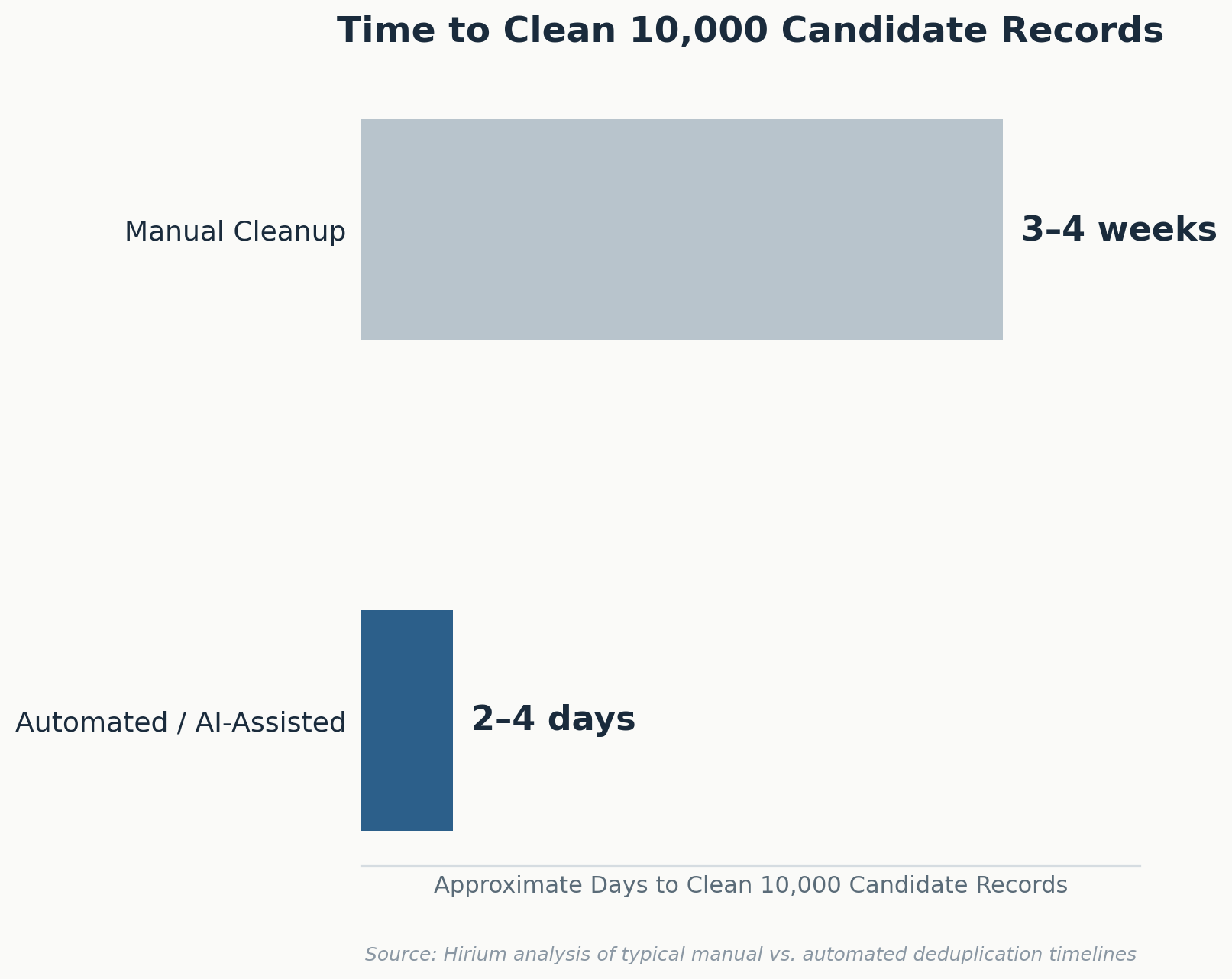
Case Studies: Cleanup in Practice
A 60-person Series B SaaS startup migrating from a spreadsheet-based tracking system to a structured ATS found that 22% of its 8,400 candidate records were duplicates, most created by parallel sourcing through referrals and a job board during the same hiring sprint. After a structured deduplication and tagging pass, search-based candidate discovery time dropped from an estimated 12 minutes per search to under 90 seconds, and two previously “lost” senior candidates were resurfaced and hired within the following quarter.
A 150-employee fintech company running high-volume hiring for a support team discovered that 31% of records marked “rejected” were tied to a single requisition closed 14 months earlier, with no indication of whether those candidates would fit newer, similar roles. Re-tagging those records as “Not a Fit Reusable” and re-screening the top 200 against three open roles produced 11 direct interview invites without any new external sourcing spend.
A 25-person early-stage startup hiring its first dedicated recruiter inherited a founder-managed spreadsheet of roughly 1,200 candidates with no consistent status field at all. Standardizing the taxonomy and migrating into a proper ATS during onboarding took under a week, and the new recruiter reported being able to fill two open roles from the existing pool rather than sourcing externally for either one a detail the founders had assumed was not possible given how disorganized the original file looked.
Manual Cleanup vs. Automated Tools: A Decision Framework
Choosing between a manual pass and automated tooling comes down to database size, ongoing volume, and how much recruiter time the team is willing to trade for tooling cost. A one-time manual cleanup can work for a small, static database, but it does not scale to teams processing continuous applicant volume, and it offers no protection against the database re-fragmenting the moment the sprint ends.
| Factor | Manual Cleanup | Automated / AI-Assisted Cleanup |
| Time to clean 10,000 records | 3–4 weeks of dedicated effort | 2–4 days with parsing + dedup rules |
| Duplicate detection accuracy | 40–60% (exact match only) | 85–95% (layered/fuzzy matching) |
| Ongoing maintenance | Requires manual quarterly review | Continuous, rule-based |
| Risk of losing good profiles | Higher (context often missed) | Lower (merge logic preserves history) |
| Upfront cost | Low tooling cost, high labor cost | Tooling cost, lower labor cost |
Smaller teams with under 2,000 active candidate records can often complete a manual cleanup in a focused sprint. Beyond that volume, the labor cost of manual deduplication typically exceeds the cost of automated tooling within the first year, particularly once the ongoing maintenance column is factored in rather than just the one-time cleanup cost.

What Most Teams Get Wrong
The most common mistake is treating a cleanup as a one-time event rather than a maintained process. Teams run an intensive dedup sprint, celebrate a clean database, and then watch it degrade back to its original state within two quarters because no automated guardrails were put in place afterward.
The second mistake is being too aggressive with deletion. Recruiters under pressure to “fix the database fast” often delete anything that looks stale, without checking whether a candidate who went quiet 14 months ago might now be exactly the right fit for a role that did not exist when they first applied. A properly run candidate database cleanup merges and archives far more often than it deletes.
The third mistake is skipping the taxonomy step and jumping straight to deduplication. Removing duplicates without standardizing tags afterward just produces a smaller version of the same disorganized database clean in count, but still unsearchable in practice.
A fourth, quieter mistake is running the cleanup without involving the recruiters who use the database daily. A data team or ops lead can identify duplicates and stale records with reasonable accuracy, but they usually cannot tell whether a candidate marked “not a fit” nine months ago was rejected for a skills gap or simply for bad timing. Recruiter input during the merge-review stage catches distinctions that pure data logic misses, and skipping this step is a common reason cleanups end up discarding context that later turns out to matter.

Where to Go From Here
A messy candidate database is rarely a technology problem on its own; it is usually a process problem that technology can fix once the process is defined. Teams that run a structured five-step cleanup, apply a simple tagging taxonomy, and pair it with automated parsing and status updates tend to stay clean far longer than teams that rely on periodic manual effort.
If your team is evaluating how to approach a candidate database cleanup before committing to new tooling, Hirium’s AI-powered ATS includes resume parsing, deduplication support, and automated status workflows as part of its core, forever-free plan worth a look if a spreadsheet or legacy system is the source of the mess in the first place.
The teams that get the most out of this process treat it as infrastructure, not a one-off favor to the recruiting team. A clean, well-tagged database compounds in value with every hire that gets sourced from it instead of paid for externally, and that value only grows as the database and the company doing the hiring gets bigger.
Frequently Asked Questions
How often should you clean your candidate database?
Most active recruiting teams benefit from a full audit every 6 months, with lightweight automated deduplication scans running weekly or monthly in between. High-volume hiring teams processing hundreds of applications weekly should lean toward monthly full reviews to prevent duplicate accumulation.
What causes duplicate candidate records in an ATS?
Duplicates most often come from candidates applying through multiple channels (career page and LinkedIn), using different email addresses across applications, or recruiters manually re-entering a candidate who was already sourced. Systems relying only on exact email matching miss most of these cases.
Can an AI resume parser prevent duplicate profiles?
Yes. An AI resume parser checks structured candidate data against existing records at the point of entry, before a new profile is created, which prevents many duplicates that manual data entry would otherwise introduce.
Is it safe to delete old candidate records?
Deleting is rarely the right first move. Archiving stale records preserves their history for future searches while keeping the active database lean, and avoids permanently losing a candidate who may be a strong fit for a role that opens later.
How do you build a candidate database tagging taxonomy?
Start with four tag categories: function/skill, source channel, pipeline status, and recency and keep the list of allowed tag values short enough that recruiters apply them consistently during daily work rather than skipping the step under time pressure.
What is the best way to organize a recruitment database?
The most reliable structure combines standardized tagging, layered deduplication logic, and automated status updates, rather than relying on any single fix. A database organized this way stays searchable without requiring a full manual cleanup every few months.
Does cleaning up a database affect ongoing hiring while it’s happening?
Not if merges are queued for review rather than auto-applied in bulk. Running the cleanup in parallel with active hiring is standard practice, provided low-confidence matches are flagged for a recruiter to confirm before any records are combined. Tools like Hirium’s centralized candidate database are built to support this kind of live review without pausing active requisitions.