AI Resume Parser Explained: How It Reads a Resume in Seconds
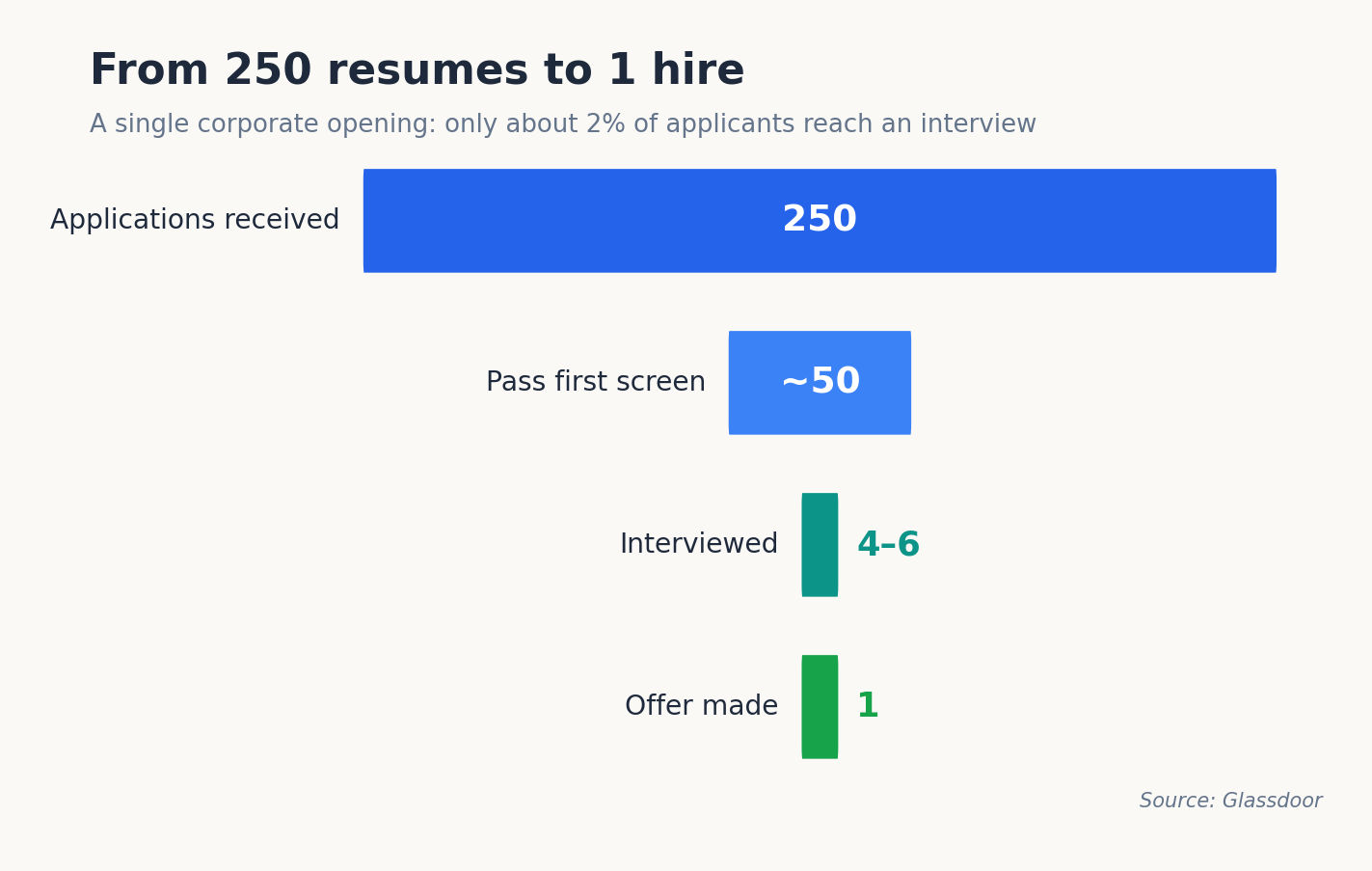
A single corporate opening pulls in roughly 250 applications, yet a recruiter gives each resume about 7.4 seconds before deciding to keep reading or move on. Run that math across a 20-role pipeline and one recruiter is staring down 5,000 documents most of which will never get a fair second look by a human being.
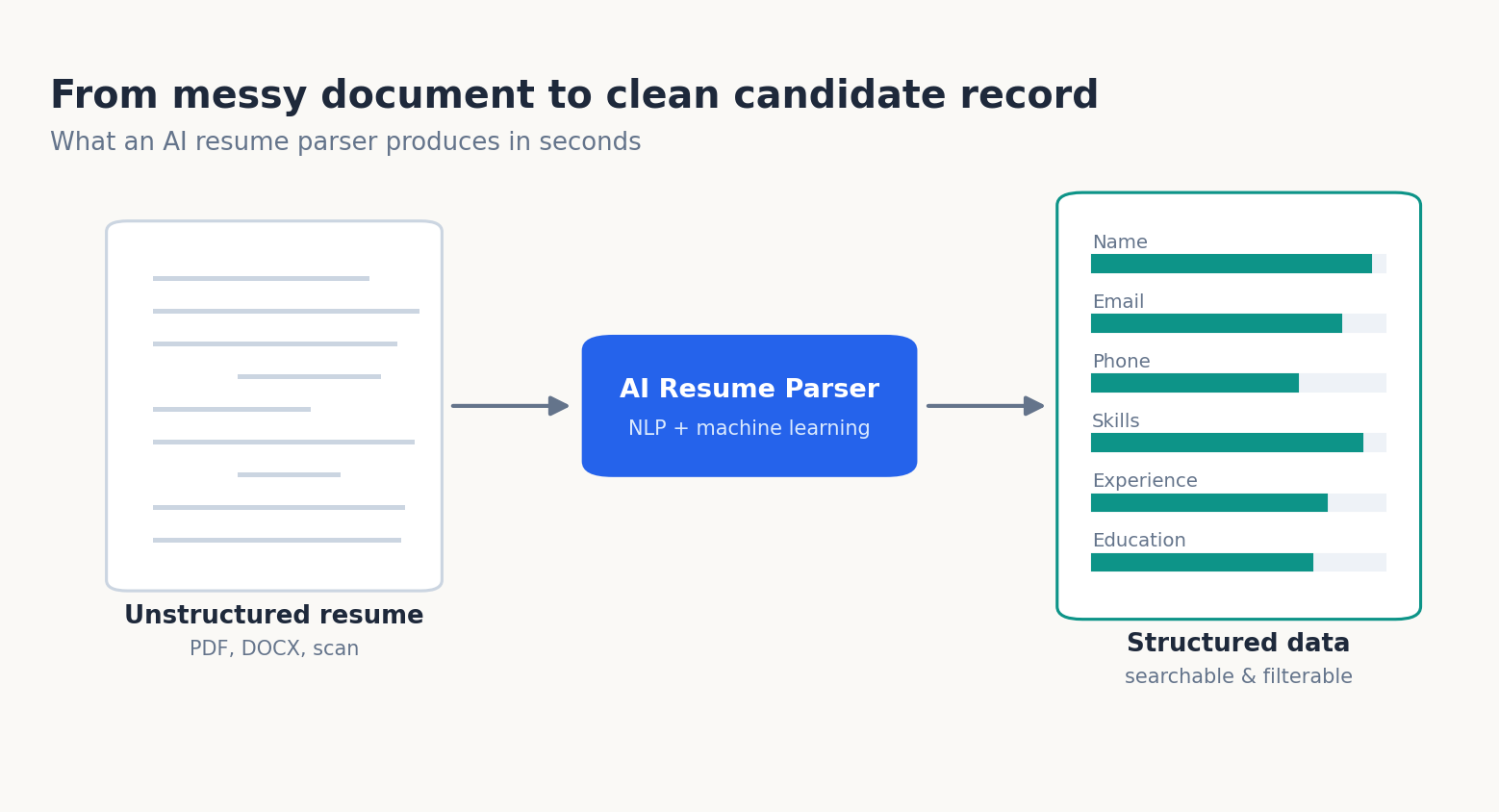
That gap between application volume and human attention is exactly where an AI Resume Parser earns its place. It does not get tired at resume number 400, it does not skim, and it does not lose the candidate whose strongest qualification was buried on page two. Instead, it reads every document the same way, extracts the same fields every time, and hands recruiters a searchable, filterable database in the time it takes to refill a coffee.
According to Glassdoor, the average corporate job opening attracts roughly 250 resumes, and only 4–6 of those candidates are ever interviewed.
This is not a futuristic promise. Modern AI Resume Parsers already convert unstructured CVs into clean records at scale, and benchmark studies put extraction accuracy on standard formats between 94% and 99%. The technology has moved from “nice to have” to load-bearing infrastructure for any team hiring at volume.
What most teams never see is the actual machinery, the sequence of steps that turns a PDF full of inconsistent formatting into a row in a candidate database. This guide breaks down that sequence in plain terms: how text gets extracted, how fields get tagged, how skills get mapped, where accuracy comes from, and the specific document types that still trip these systems up. By the end you will understand not just what the technology does, but where to trust it and where to keep a human in the loop.
What Is an AI Resume Parser?
An AI Resume Parser is software that uses natural language processing and machine learning to read an unstructured resume and convert it into structured, machine-readable data name, contact details, work history, education, and skills that an applicant tracking system can store, search, and rank automatically.
In short: it turns a document a human wrote for other humans into a record a database can query in milliseconds.
The Core Problem: Why Manual Screening Breaks at Volume
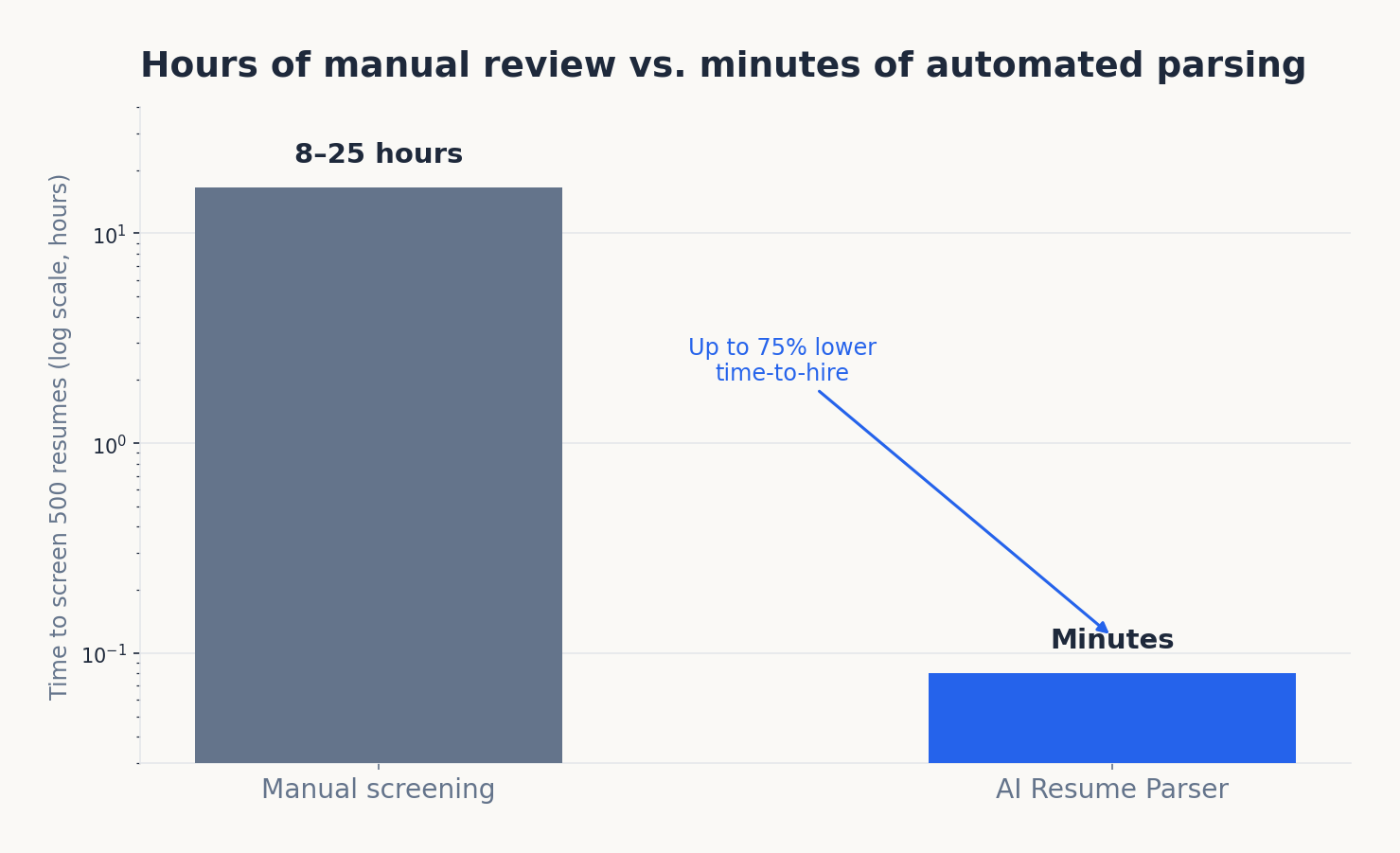
The bottleneck in early-stage hiring is rarely sourcing it is triage. When 250 resumes land for one role and a recruiter is juggling 15–25 open requisitions, the arithmetic stops working. At 30 to 90 seconds per resume, screening just 500 applications by hand consumes 8 to 25 hours of focused work before a single qualified candidate is contacted.
That time pressure produces two expensive failure modes. The first is speed: the average time-to-hire sits near 42 days, and every day a role stays open is a day of lost output and a wider window for strong candidates to accept competing offers. The second is the silent attrition of good applicants. Studies of recruiter behavior consistently find that the large majority of resumes never clear the first screen not because the candidates are unqualified, but because there was no time to read carefully.
Manual review also bakes in inconsistency. Two recruiters reviewing the same stack apply different mental shortcuts, and the same recruiter applies different standards at 9 a.m. than at hour seven of screening. Skim-reading is where subjective, non-job-related signals a school name, a familiar former employer quietly starts steering decisions.
For startups and SMBs the math is harsher still, because hiring volume spikes without a corresponding jump in recruiting headcount. A 12-person company running a hiring sprint can receive the same application load as an enterprise team ten times its size, with no spare capacity to absorb it.
There is a hidden cost layer beneath the visible one. Manual data entry copying a name, an email, and a work history from a resume into a system of record is both slow and error-prone, and those typos surface later as duplicate records, broken email sends, and candidates who simply cannot be found again. The longer a team operates without an AI Resume Parser, the more its candidate data degrades into a pile of inconsistent, half-searchable entries. This is the precise problem structured automation was built to solve.
How an AI Resume Parser Works, Step by Step
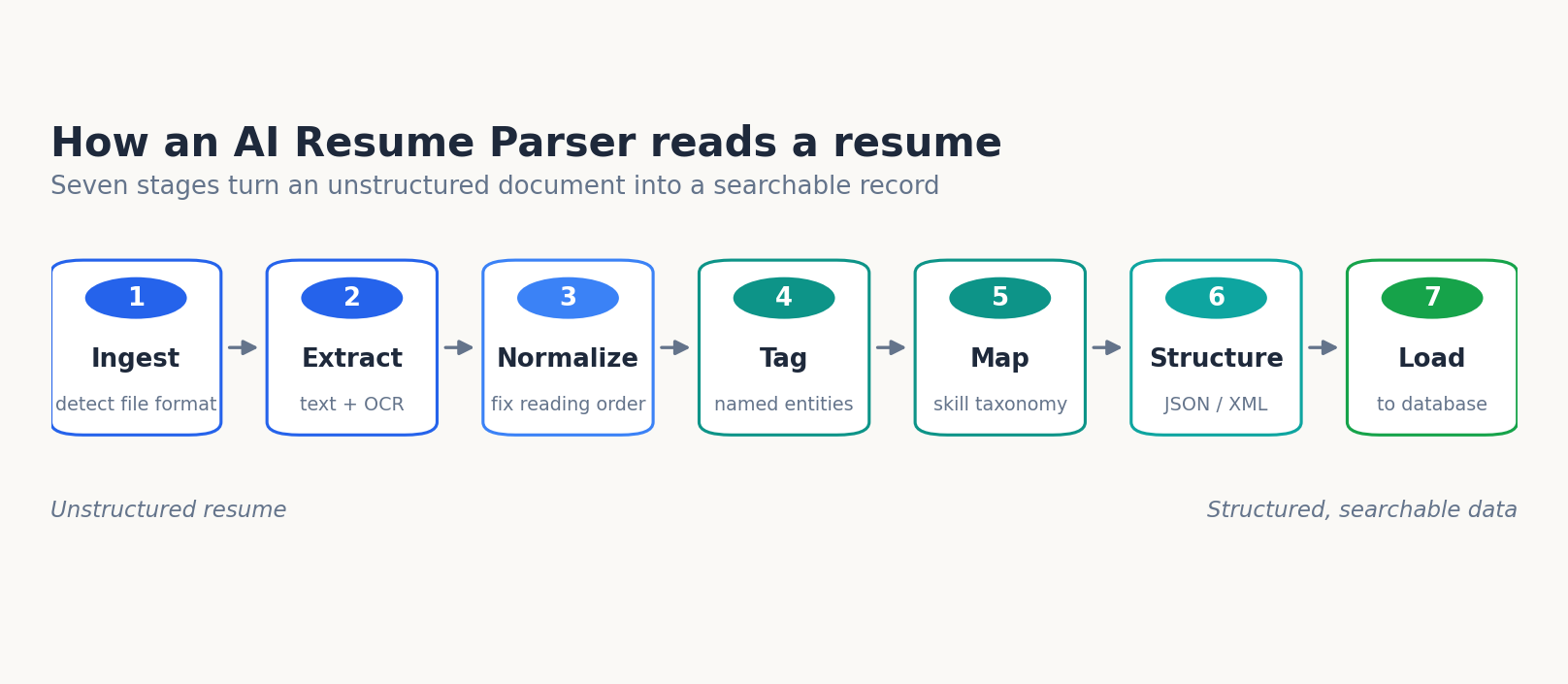
This is the part most explainers skip. A parser is not a single model that “reads” a resume the way a person does; it is a pipeline of distinct stages, each with its own job, its own failure points, and its own accuracy ceiling. Understanding how an AI resume parser works end to end is what lets you judge a vendor’s claims instead of taking them on faith.
Step 1 Text Extraction and Document Normalization
Before anything can be understood, the raw text has to come off the page. Resumes arrive as PDFs, DOCX files, RTFs, plain text, and occasionally as images, and each format stores text differently. A clean, text-based PDF is straightforward; a scanned resume is effectively a picture, which forces the system to fall back on optical character recognition to reconstruct the words pixel by pixel.
This stage also normalizes layout. Multi-column designs, headers, footers, and text boxes scramble the reading order, so the AI Resume Parser has to rebuild the logical sequence of the document figuring out that the “Skills” sidebar on the right belongs with the experience block on the left, not interleaved line by line.
Step 2 Field Tagging with Named Entity Recognition
Once the text is clean, the AI Resume Parser identifies what each piece of information actually is. Using named entity recognition, it tags spans of text as a person’s name, an email, a phone number, a company, a job title, a date range, or a degree. This is the step that separates true parsing from simple keyword spotting.
The advantage of an NLP-driven approach is context. A first-generation keyword parser might miss “Python” if it only appears inside a project description; a modern machine learning model recognizes it because it understands the surrounding verbs and nouns. The same logic lets the AI Resume Parser read “Managed a team of 15 developers” and tag it as quantified leadership experience rather than a loose string of words.
Step 3 Skill Mapping and Taxonomy Normalization
Raw extracted skills are messy. “Software Eng,” “Sftw. Developer,” and “Engineer” all point to the same role, and a usable system collapses those variants into one standardized entry using a skill taxonomy. The same normalization applies to job titles, certifications, and seniority levels.
This is what makes downstream comparison possible. Without skill mapping, a search for “JavaScript developers” misses every candidate who wrote “JS” so the cleanup at this stage directly determines how complete your later candidate searches will be.
Step 4 Structuring Data for Search and Filtering
Finally, the tagged and normalized information is written into a standardized format typically JSON or XML and pushed into the candidate database. At this point a document that no two recruiters would have read the same way becomes a uniform record: every candidate has the same fields, populated the same way, ready to query.
That structure is the whole point. It is what powers semantic search (“find me candidates with payments experience” returns fintech engineers, not just literal keyword matches), instant filtering by years of experience, and automated ranking against a role.
The full pipeline, in order:
- Ingest the file and detect its format (PDF, DOCX, image, etc.).
- Extract raw text, using OCR for scanned or image-based documents.
- Normalize layout so multi-column and boxed content reads in the correct order.
- Tag entities name, contact, employers, titles, dates, education, skills.
- Map skills and titles to a standard taxonomy to remove variant spellings.
- Structure the result into JSON/XML fields.
- Load the record into the candidate database for search, filtering, and scoring.
Architecture and Model Choices Behind the Parse
Not all parsing engines are built the same, and the architecture choice shows up directly in accuracy. Rule-based parsers the first generation rely on fixed patterns and regular expressions, which work on tidy resumes and collapse on anything unusual. A modern AI Resume Parser instead layers a machine learning model on top, so the system generalizes to formats it has never seen rather than matching rigid rules.
The current state of the art uses deep learning and, increasingly, large language models that interpret a resume the way an experienced recruiter does: by reading context, not just keywords. The practical trade-off is precision versus coverage. Many production systems run a hybrid design, a confident ML extraction with a rule-based fallback for high-stakes fields like certifications or compliance data, so a low-confidence guess never silently corrupts a record. When a vendor describes its AI Resume Parser, the architecture question to ask is simple: what happens when the model is unsure?
Integration, Cost, and Bulk Processing
Extraction accuracy means little if the structured output cannot reach your hiring stack cleanly. The strongest setups expose an API and native connectors so parsed records flow straight into the applicant tracking system without a manual export-import step because a parse that still needs re-keying has saved nobody any time. Format support should span PDF, DOCX, RTF, TXT, and image files so the AI Resume Parser handles whatever candidates actually send.
Cost is the other axis startups underestimate. Some tools price per parse, some per recruiter seat, and the model you choose quietly shapes hiring behavior per-seat pricing, for instance, discourages adding reviewers exactly when a hiring sprint needs them. Bulk resume screening is where the economics land: a capable AI Resume Parser handles hundreds or thousands of documents in a single batch, which is the difference between migrating years of archived resumes in an afternoon and never migrating them at all.
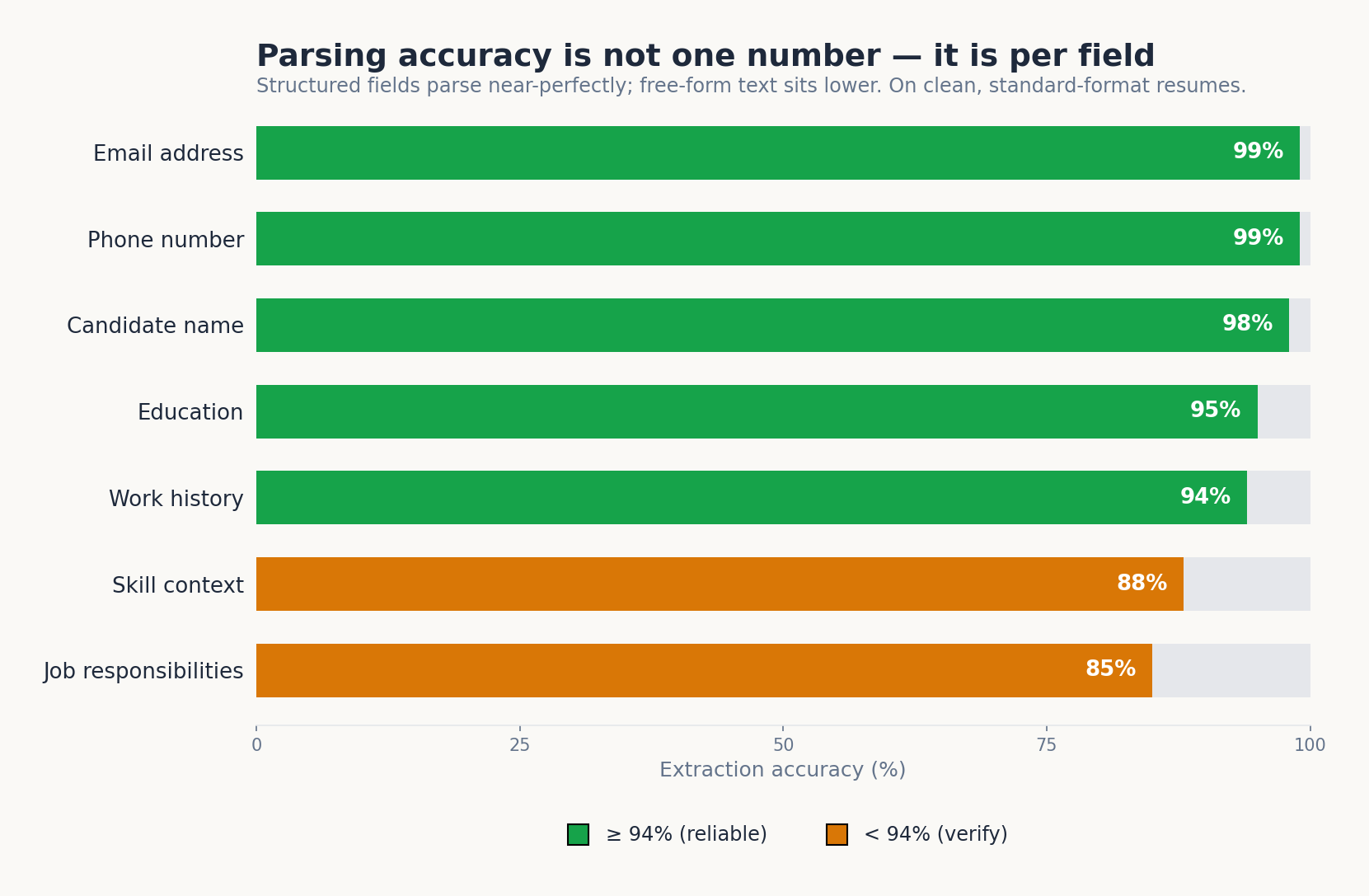
What “94% Accuracy” Actually Means
Vendors love a single accuracy number, but AI resume parser accuracy rate is not one figure, it is a per-field measurement. Names, emails, and phone numbers parse at near-perfect rates because they follow predictable patterns. Free-form fields like skill context and nuanced job responsibilities sit lower. Benchmarks generally report 94–99% on clean, chronologically formatted resumes, with accuracy declining as layouts get more creative. The honest way to read a “94%” claim for an AI Resume Parser is to ask: 94% on which fields, across which document formats?
Where Parsers Still Fail
Three document types remain genuinely hard, and pretending otherwise is how teams get burned. Parsing scanned PDF resumes depends entirely on OCR quality; a faxed or photographed CV introduces character errors that cascade into mis-tagged fields. Complex tables are the second weak spot when a candidate lays out skills or experience in a grid, the AI Resume Parser can read cells in the wrong order and stitch unrelated data together. Multi-column “designer” resumes are the third, for the same reading-order reason.
A few smaller failure modes are worth naming. Non-standard date formats and overlapping employment ranges confuse experience calculations. Heavy graphics, logos, and embedded charts can swallow nearby text. And resumes in mixed languages stress the model unless it was trained for multilingual input. None of these makes an AI Resume Parser unusable; they make the case for keeping a correction step in the workflow rather than trusting every field blindly.
The compliance dimension matters here too. Because parsed data flows automatically into hiring decisions, mature systems keep audit trails, support data-privacy requirements, and allow recruiters to correct extractions that feed back in to retrain the model over time.
AI Resume Screening: What Happens After the Parse
Parsing is extraction; AI Resume Screening is judgment. Once a resume is structured, the screening layer scores it against the role weighing skills, experience depth, and qualifications and surfaces the strongest matches first. The cleaner the parse, the more reliable the score, which is why an AI Resume Parser and the screening layer are so tightly coupled.
This is also where structured data starts compounding in value. A well-parsed record makes candidate shortlisting close to instant: instead of reading 250 resumes, a recruiter reviews a ranked list and spends their attention on the top tier. Reported gains are substantial; an AI Resume Parser feeding a matching layer can cut time-to-hire by up to 75% and improve match accuracy by around 40% over plain keyword search.
Demo suggestion for publishing: Add a short screen recording or GIF here showing a resume dropped into the AI Resume Parser and the structured fields name, skills, experience, education populating in real time, followed by the candidate appearing in a ranked shortlist. A side-by-side of raw resume and parsed output makes the value obvious at a glance.
Candidate Profile Management at Scale
Strong Candidate Profile Management is the quiet payoff of good parsing. Every applicant becomes a complete, consistent profile in one place, so a candidate who was not right for a March role can be resurfaced in seconds for a June opening turning a one-time application pool into a reusable talent pipeline. For SMBs that hire in bursts, this rediscovery effect often delivers more value than the initial screen.
Structured profiles also feed the rest of the hiring stack. They populate automated Recruitment Email Templates with the correct candidate details for status updates, interview invitations, and rejections, removing the copy-paste errors that creep in under volume. And they close the loop with the Job Posting Software that generated the application in the first place, so a role advertised across multiple channels lands every applicant into one normalized database rather than a scatter of inboxes and spreadsheets.
One platform built around this flow, Hirium, treats parsing as the entry point to that wider system rather than a standalone trick the parse feeds screening, shortlisting, tracking, and outreach without manual re-keying.
Case Study: Two Real-World Hiring Scenarios
A 30-person SaaS startup running an engineering hiring sprint received over 600 applications across four roles in three weeks. Manual screening would have consumed an estimated 15–20 recruiter hours per week; routing every resume through an AI Resume Parser and screening layer compressed the first-pass review to under two hours total, and the team filled all four roles roughly a third faster than its previous sprint. Just as important, no qualified applicant was lost to fatigue, because every resume was read with the same rigor as the first.
In a second scenario, a fast-growing services SMB migrated several years of archived resumes, many of them older scanned PDFs into a centralized candidate database. Re-parsing that backlog with an AI Resume Parser surfaced dozens of previously buried qualified candidates, two of whom were hired for new roles without spending a rupee on fresh sourcing. The outcome that mattered was not speed but recovery: value the company already owned but could not previously search. For an SMB watching its cost-per-hire, rediscovering a candidate is close to free compared with running a new sourcing campaign.
Choosing an AI Resume Parser: A Decision Framework
Not every parser fits every team, and the right choice depends less on headline accuracy than on how an AI Resume Parser behaves on your actual document mix and how cleanly it connects to the rest of your hiring workflow. The table below frames the trade-offs that matter when evaluating the best resume parsing software for startups and SMBs.
| Evaluation criterion | What to look for | Why it matters |
| Format coverage | PDF, DOCX, RTF, and reliable OCR for scans | Your inbound mix is messier than vendor demos |
| Accuracy transparency | Per-field rates, not one blended number | “94%” hides where the misses actually happen |
| ATS integration | Native fit with your candidate database | A parse that needs re-keying saves no time |
| Correction loop | Easy edits that retrain the model | Real-world layouts drift; the tool should adapt |
| Pricing model | Flat, predictable, no per-recruiter fees | Volume hiring shouldn’t penalize you per seat |
A short rule of thumb: if a vendor will not show you parsing results on a batch of your resumes including the ugly scanned ones treat the published accuracy figure as marketing, not evidence.
Weighting these criteria depends on your situation. A high-volume consumer brand drowning in scanned applications should weigh OCR and format coverage heavily. A technical team hiring engineers should prioritize skill-mapping depth and taxonomy quality, since that determines whether a search for niche frameworks actually returns the right people. And any team that hires in unpredictable bursts should care most about pricing structure and integration, because an AI Resume Parser that punishes you for adding reviewers or forces manual data transfer will erode its own time savings the moment volume climbs.
What Most Teams Get Wrong About Resume Parsing
The most common mistake is treating the parser as a magic filter and walking away. AI resume parser vs ATS solutions is a real distinction, but neither one should be making final cuts unsupervised. The system’s job is to triage and rank so humans spend their judgment where it counts, not to auto-reject candidates no one ever sees.
The second mistake is ignoring the input. Teams obsess over the model and never audit their own document pipeline, then blame the AI Resume Parser when accuracy dips when the real cause is a flood of scanned PDFs or table-heavy templates the system was never tuned for. Parsing quality is an input problem as much as a model problem.
The third, and most costly, is underusing the structured data once it exists. Most teams use parsing only for the live role and let every other profile go cold. The genuinely high-leverage move is treating the parsed candidate database as a permanent, searchable asset, the difference between paying to source the same talent twice and rediscovering candidates you already have. The parse is cheap; the database it builds is the durable advantage.
A fourth, quieter error is skipping the human correction loop. Teams deploy an AI Resume Parser, see strong accuracy in the demo, and never wire in a way for recruiters to fix the occasional mis-tag. Those corrections are not busywork in a well-built system; they retrain the model, so the parser that handles your particular resume mix gets measurably better over the first few months. Treating extraction as set-and-forget leaves that compounding improvement on the table.
Frequently Asked Questions
How accurate is an AI resume parser?
On clean, well-structured resumes, modern parsers report 94–99% accuracy, but the number varies by field. Names, emails, and phone numbers extract at near-perfect rates, while free-form skill context and nuanced responsibilities are lower. Accuracy also drops on creative layouts and scanned documents, so always ask for per-field results on your own resume mix rather than a single blended figure.
Can an AI resume parser read scanned PDFs?
Yes, but with caveats. A scanned resume is an image, so the AI Resume Parser relies on optical character recognition to reconstruct the text first. Clear, high-resolution scans parse well; faxed, photographed, or low-quality scans introduce character errors that can cascade into mis-tagged fields. If your inbound includes many scans, OCR quality should be a primary evaluation criterion.
How does a parser handle tables and multi-column resumes?
This is one of the harder cases. Tables and multi-column “designer” layouts disrupt the natural reading order, so a weaker engine may read cells in the wrong sequence and merge unrelated information. Stronger systems rebuild the document’s logical structure before tagging fields, but no parser is flawless here; these formats are worth spot-checking manually during evaluation.
Is AI resume parsing the same as AI Resume Screening?
No. Parsing is extraction turning an unstructured resume into structured fields. Screening is the judgment layer that scores and ranks those structured records against a role. They work in sequence: screening quality depends directly on parsing quality, since a model can only rank candidates accurately if the underlying data was extracted cleanly in the first place.
How long does it take to parse one resume?
Effectively seconds are often a fraction of a second per document and a modern AI Resume Parser processes hundreds or thousands in bulk. The practical time saving is enormous: screening 500 resumes manually can take 8–25 hours, while bulk parsing structures the same volume almost instantly, leaving recruiters to spend their hours on the shortlist rather than the slush pile.
Does AI resume parsing introduce bias?
It can reduce or amplify bias depending on implementation. Because parsing evaluates structured data points rather than gut impressions, it removes some of the subjective signals that creep into tired human screening. But models trained on biased historical data can inherit those patterns, which is why audit trails, anonymization options, and human oversight on final decisions are non-negotiable. If you are weighing a tool against your fairness goals, that is a good moment to talk to a specialist.
What is the best resume parsing software for startups?
There is no single answer, but the right fit for a startup usually prioritizes three things over raw accuracy claims: predictable flat pricing that does not penalize you per recruiter, native integration so parsed records land directly in your candidate database, and reliable handling of messy real-world formats. The best test is practical: run your own resume backlog through an AI Resume Parser on a free or trial plan and judge the structured output before you commit a budget.
Where to Go From Here
If you are evaluating an AI Resume Parser and want to pressure-test it before committing, do one thing first: run a real batch of your own resumes including the scanned and table-heavy ones through any tool you are considering, and check the structured output field by field. That single test tells you more than any published accuracy number.
When you are ready to see an AI Resume Parser inside a full hiring workflow screening, shortlisting, tracking, and candidate rediscovery in one place Hirium offers a forever-free plan with no credit card required, so you can test the parse on your own pipeline before scaling up. Start with your messiest stack of resumes and watch what comes out the other side.